
Go and SQLite in the Cloud
Why SQLite and Go in the cloud are a great match, getting started, best practices, and more.
Last updated June 2023 for Go 1.20.
Why SQLite and Go?
I love the intersection of the cloud and "boring" old technologies. SQLite and the cloud is a perfect example of this. SQLite has been around forever, runs on literally billions of devices (it’s in space!) and is super robust and well-tested. You probably have it running on the phone in your pocket already.
SQLite is currently in something of a renaissance, because it’s increasingly being used on the . Have a look at Cloudflare’s D1, or what fly.io are doing with SQLite, Litestream, and LiteFS.
But even if you’re not doing anything fancy and just have a service running somewhere, with a persistent disk attached, SQLite could be worth another look instead of the usual Postgres/MySQL central server setup.
Why? Because it’s just so crazy fast, conceptually and practically simple, but still covers the needs of (I’d wager) most of the web apps out there. It has , full SQL support, great tooling, and did I say it was fast? We’re talking microseconds instead of milliseconds for queries.
Convinced to try it out? In this article, I’ll show you:
- how to set up an app with SQLite and Go, with idiomatic, production-ready, best-practice code;
- how to test your app efficiently;
- some Go-specific data modelling best practices; and
- how to deploy it all to the cloud.
What I won’t show you this time is how to do distributed SQLite across several nodes in the cloud edge. Check out my article on distributed SQLite with LiteFS for that, which builds on this article. I also won’t show you how to use SQL.
This is a living document. Got any comments, questions, or suggestions? Send me an email or find me on Mastodon.
Also check out the interesting Hacker News discussion for this article.
Let’s go!
The Go SQLite app
The app is a tiny web app with a blog, where articles can be created, viewed, and searched.
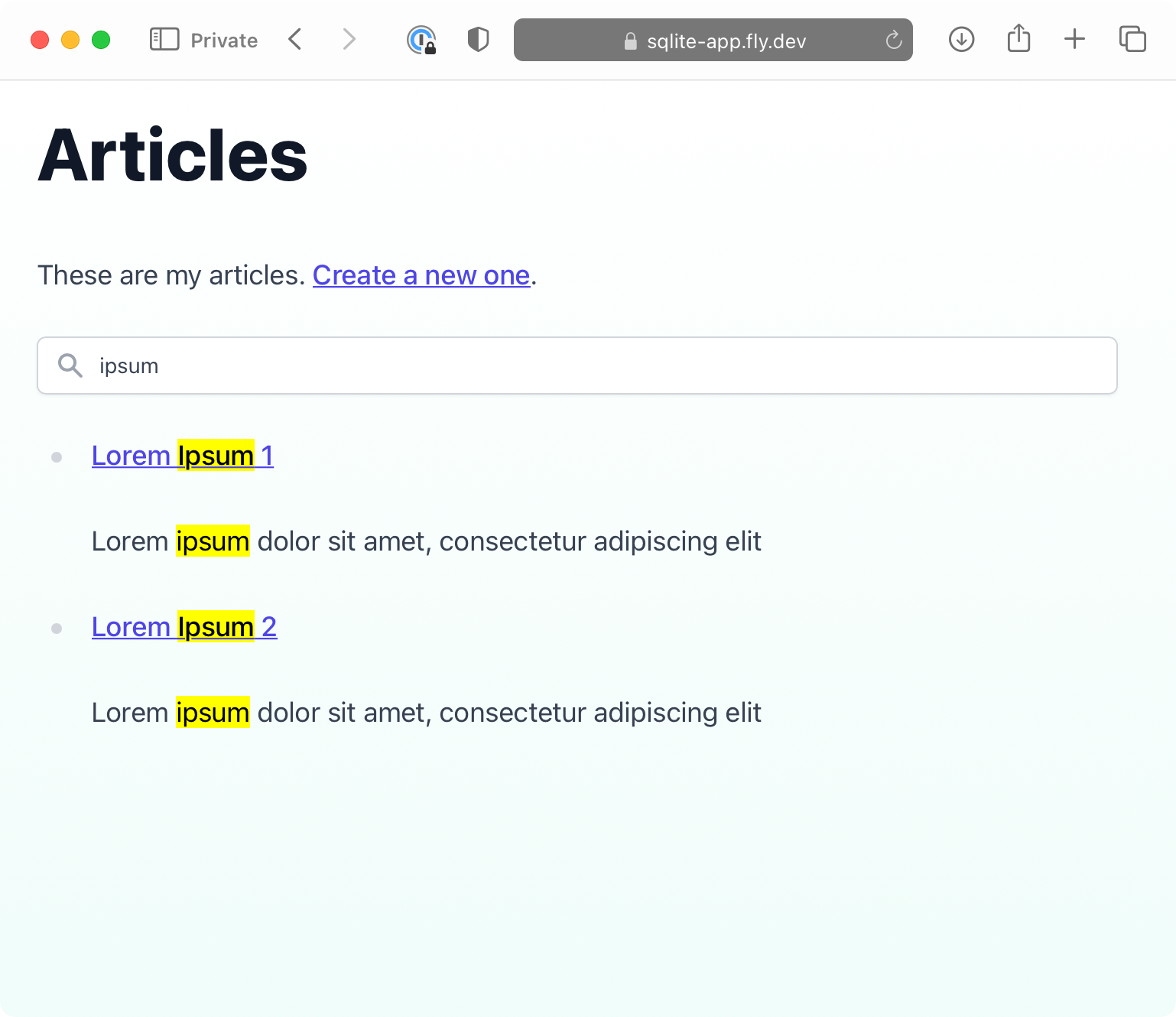
I’ll show you the relevant parts of the app on this page. Check out all the code of the sqlite-app on Github, and poke around the online demo here. If you want to follow along, clone the repo, run make migrate-up start and then go to localhost:8080. Try it, I’ll wait.
The output should look something like this:
$ make migrate-up start
go run ./cmd/migrate up
2022/11/03 12:28:57 database.go:61: Connecting to database at file:app.db?_journal=WAL&_timeout=5000&_fk=true
2022/11/03 12:28:57 database.go:69: Setting connection pool options ( max open connections: 1 , max idle connections: 1 , connection max lifetime: 0s , connection max idle time: 0s )
2022/11/03 12:28:57 main.go:41: Migrated up
go run -tags fts5 ./cmd/server
2022/11/03 12:29:18 main.go:20: Starting
2022/11/03 12:29:18 database.go:61: Connecting to database at file:app.db?_journal=WAL&_timeout=5000&_fk=true
2022/11/03 12:29:18 database.go:69: Setting connection pool options ( max open connections: 5 , max idle connections: 5 , connection max lifetime: 1h0m0s , connection max idle time: 1h0m0s )
2022/11/03 12:29:18 server.go:60: Starting
2022/11/03 12:29:18 server.go:64: Listening on http://localhost:8080The database
The storage to SQLite is handled in the Database struct. It’s constructed with a database URL, a few connection parameters, and a logger. Have a look at the code, and we’ll go through it:
sql/database.gopackage sql import ( "context" "embed" "io" "io/fs" "log" "time" "github.com/jmoiron/sqlx" "github.com/maragudk/migrate" _ "github.com/mattn/go-sqlite3" ) type Database struct { DB *sqlx.DB url string maxOpenConnections int maxIdleConnections int connectionMaxLifetime time.Duration connectionMaxIdleTime time.Duration log *log.Logger } type NewDatabaseOptions struct { URL string MaxOpenConnections int MaxIdleConnections int ConnectionMaxLifetime time.Duration ConnectionMaxIdleTime time.Duration Log *log.Logger } // NewDatabase with the given options. // If no logger is provided, logs are discarded. func NewDatabase(opts NewDatabaseOptions) *Database { if opts.Log == nil { opts.Log = log.New(io.Discard, "", 0) } // - Set WAL mode (not strictly necessary each time because it's persisted in the database, but good for first run) // - Set busy timeout, so concurrent writers wait on each other instead of erroring immediately // - Enable foreign key checks opts.URL += "?_journal=WAL&_timeout=5000&_fk=true" return &Database{ url: opts.URL, maxOpenConnections: opts.MaxOpenConnections, maxIdleConnections: opts.MaxIdleConnections, connectionMaxLifetime: opts.ConnectionMaxLifetime, connectionMaxIdleTime: opts.ConnectionMaxIdleTime, log: opts.Log, } } func (d *Database) Connect() error { ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second) defer cancel() d.log.Println("Connecting to database at", d.url) var err error d.DB, err = sqlx.ConnectContext(ctx, "sqlite3", d.url) if err != nil { return err } d.log.Println("Setting connection pool options (", "max open connections:", d.maxOpenConnections, ", max idle connections:", d.maxIdleConnections, ", connection max lifetime:", d.connectionMaxLifetime, ", connection max idle time:", d.connectionMaxIdleTime, ")") d.DB.SetMaxOpenConns(d.maxOpenConnections) d.DB.SetMaxIdleConns(d.maxIdleConnections) d.DB.SetConnMaxLifetime(d.connectionMaxLifetime) d.DB.SetConnMaxIdleTime(d.connectionMaxIdleTime) return nil } // …
First, the imports. I’m using the Go SQLite database driver from github.com/mattn/go-sqlite3, which basically uses the official SQLite C library directly, wired up to be easy to use from Go.
Another import is github.com/jmoiron/sqlx, which is an excellent SQL helper library which makes querying the database much easier.
After that, it gets interesting in NewDatabase. We set three options for the SQL driver as URL query parameters:
_journal=WAL means we set the journal mode to WAL (Write-Ahead Log). What’s a journal mode? It’s about how SQLite handles writing data to disk safely.
The default journal mode in SQLite is a so-called rollback journal, which means that changes are written directly to the main database file, and the old data is kept in the rollback journal in a separate file. When data is written, readers are blocked, and when data is read, writers are blocked!
Because of this, we use the WAL journal mode instead, where readers don’t block writers and writers don’t block readers. (Writers still block writers, though, because write access is serialized. See below.) As the name implies, the WAL receives all new writes, and readers can keep reading from the main database file. (Readers also read from the WAL once changes are committed, but that’s a detail we don’t need to consider right now.)
Note: The WAL journal mode is actually persisted to the database file the first time it’s opened like this, but to keep things simple, we just set the option every time. It’s just a no-op then.
_timeout=5000 sets a busy timeout to 5000 milliseconds, or 5 seconds. There can only be one writer at a time in SQLite, so if another writer wants concurrent access, it would normally be blocked and return an error. If the busy timeout is set, the writer will instead wait up to that timeout for write access, and only then return an error. So it’s a good idea to set this if you ever think you will have concurrent writes, and of course in web apps, you will.
_fk=true enables foreign key checking. Why do I need to enable that explicitly?!, you might rightfully ask. The answer is, for backwards compatibility with older versions of SQLite. This can also be set at compile-time, but better safe than sorry here, in my opinion. Referential integrity FTW.
After that, the Connect method actually establishes the connection using the sqlite3 driver name and the database URL passed into the struct. It sets a few sane connection options, logs them, and that’s it.
The schema
In order to save our articles and make them searchable, we’ll contruct an articles table and an articles_fts virtual table.
sql/migrations/1667384958-articles.up.sqlcreate table articles ( id integer primary key, title text not null, content text not null, created text not null default (strftime('%Y-%m-%dT%H:%M:%fZ')), updated text not null default (strftime('%Y-%m-%dT%H:%M:%fZ')) ) strict; create index articles_created_idx on articles (created); create trigger articles_updated_timestamp after update on articles begin update articles set updated = strftime('%Y-%m-%dT%H:%M:%fZ') where id = old.id; end;
We want an automatically generated ID for our articles. In SQLite, in order to have an explicit, auto-incrementing integer primary key, the type has to be integer primary key (NOT int primary key, then it won’t work 🙄), so that’s what we use here.
I’ve added create and update timestamps here as strings (the text type). Why not write default current_timestamp instead? Because it’s not quite the format we should all be using, namely ISO8601/RFC3339. select current_timestamp outputs something like 2025-08-15 06:06:20, which lacks the T separator, has no timezone info, and has no sub-second precision.
strftime('%Y-%m-%dT%H:%M:%fZ') almost matches the format given in the Go stdlib at time.RFC3339Nano, except it’s millisecond precision. Because mixing timestamps with different precisions with a timezone suffix doesn’t sort correctly chronologically (for example 2022-11-11T12:34:56.000Z sorts after 2022-11-11T12:34:56.000000001Z), we use our own time format called rfc3339Milli later. We’ll use that for parsing and serializing time in Go code.
We’re also adding an index on the creation time for good measure, and a trigger to update the updated timestamp automatically after update. Nifty!
Waaaait, what’s that strict keyword? It’s a usage of the relatively new strict tables feature (from 2021). Normally, even though you can declare types on table columns in SQLite, by default the types are not enforced on insert/update and you can insert whatever you like. The strict keyword restricts this, which is arguably more aligned with how we use the database in Go. Unfortunately, you need to remember to write this after each create table declaration in every migration you ever write, instead of it being a global feature you can enable (like foreign key support). Somebody should write a linter for that (you? 😉).
Onto the full text search virtual table:
sql/migrations/1667395622-fts.up.sqlcreate virtual table articles_fts using fts5(title, content, tokenize = porter, content = 'articles', content_rowid = 'id'); create trigger articles_after_insert after insert on articles begin insert into articles_fts (rowid, title, content) values (new.id, new.title, new.content); end; create trigger articles_fts_after_update after update on articles begin insert into articles_fts (articles_fts, rowid, title, content) values('delete', old.id, old.title, old.content); insert into articles_fts (rowid, title, content) values (new.id, new.title, new.content); end; create trigger articles_fts_after_delete after delete on articles begin insert into articles_fts (articles_fts, rowid, title, content) values('delete', old.id, old.title, old.content); end;
Here, we use the FTS5 extension to create a virtual table that will hold our full-text search indexes. I want to have indexes on the article title and content, so that’s what I’m declaring here. You can pass in a few settings, which I’ve done to set the text tokenizer to porter (which does word stemming). I’ve also enabled external content tables, which means that the virtual table won’t hold a copy of the source data, but refer it to the articles table. The column to join on is set by the content_rowid option.
Full-text search indexes are not kept up to date automatically, so the insert/update/delete triggers are used for that. The syntax for deleting an old row is a bit weird (basically insert a row with a delete string), but that’s how it is.
The query methods
The app uses a few methods on Database to create, read, and search articles:
sql/articles.gopackage sql import ( "context" "database/sql" "errors" "strings" "github.com/maragudk/sqlite-app/model" ) // GetTOC of all articles with no content. func (d *Database) GetTOC(ctx context.Context) ([]model.Article, error) { var as []model.Article err := d.DB.SelectContext(ctx, &as, `select id, title from articles order by created desc`) return as, err } // CreateArticle with title and content, ignoring any ID or timestamps. func (d *Database) CreateArticle(ctx context.Context, a model.Article) error { a.Title = strings.ReplaceAll(a.Title, "␟", "") a.Content = strings.ReplaceAll(a.Content, "␟", "") _, err := d.DB.NamedExecContext(ctx, `insert into articles (title, content) values (:title, :content)`, a) return err } // GetArticle by ID, returning nil if no such ID exists. // If search is not empty, highlight the given search query in the title and content. func (d *Database) GetArticle(ctx context.Context, id int, search string) (*model.Article, error) { var a model.Article query := `select * from articles where id = ?` var args []any args = append(args, id) if search != "" { query = ` select a.id, highlight(articles_fts, 0, '␟', '␟') title, highlight(articles_fts, 1, '␟', '␟') content, a.created, a.updated from articles a join articles_fts af on (af.rowid = a.id) where id = ? and articles_fts match ?` args = append(args, escapeSearch(search)) } if err := d.DB.GetContext(ctx, &a, query, args...); err != nil { if errors.Is(err, sql.ErrNoRows) { return nil, nil } return nil, err } return &a, nil } // SearchArticles with the given search query. Matches in titles are highlighted with the unit separator character ␟. // Matches in content return a snippet of the content, also highlighted with the unit separator character ␟. // Results are ordered by the internal rank of fts5. // See https://www.sqlite.org/fts5.html func (d *Database) SearchArticles(ctx context.Context, search string) ([]model.Article, error) { var as []model.Article query := ` select a.id, highlight(articles_fts, 0, '␟', '␟') title, snippet(articles_fts, 1, '␟', '␟', '', 8) content, a.created, a.updated from articles a join articles_fts af on (af.rowid = a.id) where articles_fts match ? order by rank` err := d.DB.SelectContext(ctx, &as, query, escapeSearch(search)) return as, err } func escapeSearch(s string) string { s = strings.ReplaceAll(s, `"`, `""`) return `"` + s + `"` }
Let’s start with the most interesting method. SearchArticles selects from the articles table and the articles_fts virtual table. For the title, the optional search query is used to highlight relevant terms, delimited by the unit separator character ␟. (In the HTML views, that character is later replaced by a <mark> tag.) Similarly, for the article content we fetch a highlighted snippet with a maximum of 8 context words.
To make this work, we’re using the match operator on the articles_fts table. We could just use the equality operator, but I think this makes it more clear that it’s a search.
Finally, the search is ordered by the special rank column, which orders results by some measure of relevancy.
GetArticle is pretty similar when a search query is given, except it returns the whole highlighted content instead of just a snippet. When no search query is given, it just returns all the article data verbatim.
CreateArticle makes sure our highlight separator character isn’t in the input text, and otherwise just saves the article. Remember, the fts index is updated via triggers.
Finally, GetTOC gets just the article IDs and titles, ordered by creation date.
And voila, that’s basically all you need to create, read, and search articles.
The model
You may have noticed the model package above. Here’s our model:
sql/articles.gopackage model import ( "database/sql/driver" "time" "github.com/maragudk/errors" ) type Article struct { ID int Title string Content string Created Time Updated Time } type Time struct { T time.Time } // rfc3339Milli is like time.RFC3339Nano, but with millisecond precision, and fractional seconds do not have trailing // zeros removed. const rfc3339Milli = "2006-01-02T15:04:05.000Z07:00" // Value satisfies driver.Valuer interface. func (t *Time) Value() (driver.Value, error) { return t.T.UTC().Format(rfc3339Milli), nil } // Scan satisfies sql.Scanner interface. func (t *Time) Scan(src any) error { if src == nil { return nil } s, ok := src.(string) if !ok { return errors.Newf("error scanning time, got %+v", src) } parsedT, err := time.Parse(rfc3339Milli, s) if err != nil { return err } t.T = parsedT.UTC() return nil }
The Article struct holds all our data. Because we want control of how the timestamps are (de)serialized, we’ve added a custom Time struct, which has methods that satisfy the driver.Valuer and sql.Scanner interfaces. That way, we know that any time format in our database always matches rfc3339Milli in UTC.
Why am I using incrementing integers for IDs here? Because it’s easy. Sometimes you want something like string UUIDs instead, for example if you don’t want to show how many of something you have (e.g. users, purchases, that slightly embarassing plush frog collection). In that case, take a look at github.com/google/uuid, which also has SQL (de)serialization built it.
Testing
How do we know this works and keeps working? Tests!
sql/articles_test.gopackage sql_test import ( "context" "testing" "time" "github.com/stretchr/testify/require" "github.com/maragudk/sqlite-app/model" "github.com/maragudk/sqlite-app/sqltest" ) func TestDatabase_GetTOC(t *testing.T) { t.Run("gets all articles with only id and title reverse chronological order", func(t *testing.T) { db := sqltest.CreateDatabase(t) err := db.CreateArticle(context.Background(), model.Article{ Title: "Foo", Content: "Bar", }) require.NoError(t, err) err = db.CreateArticle(context.Background(), model.Article{ Title: "Baz", Content: "Boo", }) require.NoError(t, err) as, err := db.GetTOC(context.Background()) require.NoError(t, err) require.Len(t, as, 2) require.Equal(t, 2, as[0].ID) require.Equal(t, "Baz", as[0].Title) require.Equal(t, "", as[0].Content) require.Equal(t, 1, as[1].ID) }) } func TestDatabase_CreateArticle(t *testing.T) { t.Run("discards the unit separator character in title and content", func(t *testing.T) { db := sqltest.CreateDatabase(t) err := db.CreateArticle(context.Background(), model.Article{ Title: "Foo␟", Content: "Bar␟", }) require.NoError(t, err) a, err := db.GetArticle(context.Background(), 1, "") require.NoError(t, err) require.NotNil(t, a) require.Equal(t, "Foo", a.Title) require.Equal(t, "Bar", a.Content) }) } func TestDatabase_GetArticle(t *testing.T) { t.Run("gets an article", func(t *testing.T) { db := sqltest.CreateDatabase(t) err := db.CreateArticle(context.Background(), model.Article{ Title: "Foo", Content: "Bar", }) require.NoError(t, err) a, err := db.GetArticle(context.Background(), 1, "") require.NoError(t, err) require.NotNil(t, a) require.Equal(t, 1, a.ID) require.Equal(t, "Foo", a.Title) require.Equal(t, "Bar", a.Content) require.WithinDuration(t, time.Now(), a.Created.T, time.Second) require.WithinDuration(t, time.Now(), a.Updated.T, time.Second) }) t.Run("returns nil on no such id", func(t *testing.T) { db := sqltest.CreateDatabase(t) a, err := db.GetArticle(context.Background(), 1, "") require.NoError(t, err) require.Nil(t, a) }) t.Run("highlights substrings if search given", func(t *testing.T) { db := sqltest.CreateDatabase(t) err := db.CreateArticle(context.Background(), model.Article{ Title: "The Foo Bar", Content: "Foo Bar Foo", }) require.NoError(t, err) a, err := db.GetArticle(context.Background(), 1, "foo") require.NoError(t, err) require.NotNil(t, a) require.Equal(t, "The ␟Foo␟ Bar", a.Title) require.Equal(t, "␟Foo␟ Bar ␟Foo␟", a.Content) }) } func TestDatabase_SearchArticles(t *testing.T) { db := sqltest.CreateDatabase(t) err := db.CreateArticle(context.Background(), model.Article{ Title: "The Foo is great", Content: "I wish that bar was also, but who am I to complain?", }) require.NoError(t, err) err = db.CreateArticle(context.Background(), model.Article{ Title: "Bar me up a notch", Content: "Boo ya.", }) require.NoError(t, err) t.Run("searches article titles and content and highlights and makes snippets", func(t *testing.T) { as, err := db.SearchArticles(context.Background(), "bar") require.NoError(t, err) require.Len(t, as, 2) require.Equal(t, "␟Bar␟ me up a notch", as[0].Title) require.Equal(t, "Boo ya.", as[0].Content) require.Equal(t, "The Foo is great", as[1].Title) require.Equal(t, "I wish that ␟bar␟ was also, but who", as[1].Content) }) }
The tests themselves are pretty unremarkable, but have a quick read.
What makes this work is in the sqltest helper package:
sqltest/database.gopackage sqltest import ( "context" "testing" "github.com/maragudk/env" "github.com/maragudk/sqlite-app/sql" ) // CreateDatabase for testing. func CreateDatabase(t *testing.T) *sql.Database { t.Helper() _ = env.Load("../.env-test") db := sql.NewDatabase(sql.NewDatabaseOptions{ URL: env.GetStringOrDefault("DATABASE_URL", ":memory:"), MaxOpenConnections: 1, MaxIdleConnections: 1, }) if err := db.Connect(); err != nil { t.Fatal(err) } if err := db.MigrateUp(context.Background()); err != nil { t.Fatal(err) } return db }
Each test gets its own in-memory database that’s automatically deleted after the test run! And it’s super fast! All tests in the repo run in under 1 second on my machine, and that’s just beautiful. It very much matches Go’s philosophy of tools being fast. (Can you tell I really love this?)
The rest
I’m not going to show you the rest of the app code, as it’s not very specific to SQLite. Just know that the HTTP server, routes, and HTTP handlers are in the http package, and the HTML views are in the (you guessed it) html package. I haven’t added tests for these, but probably would in a real production app. If you’d like to try, I would start with the NewArticle handler.
Deploying to the cloud
Web apps are just more fun if they don’t just run locally, and I’ll show you how easy it is to get this app running in the cloud. Let’s give fly.io a spin. Sign up for an account with them if you don’t have one already, and install the Fly CLI. Then, running fly launch will give you something like this:
$ fly launch
An existing fly.toml file was found for app sqlite-app
? Would you like to copy its configuration to the new app? Yes
Creating app in /Users/markus/Developer/my-sqlite-app
Scanning source code
Detected a Dockerfile app
? Create .dockerignore from 1 .gitignore files? No
? Choose an app name (leave blank to generate one): my-sqlite-app
? Select Organization: Markus (personal)
? Choose a region for deployment: Frankfurt, Germany (fra)
Created app my-sqlite-app in organization personal
Wrote config file fly.toml
? Would you like to set up a Postgresql database now? No
? Would you like to deploy now? No
Your app is ready! Deploy with flyctl deployMake sure to say yes to copying the existing configuration, because I’ve made it easy for you. It’s just a standard configuration, but makes sure to mount the persistent volume we’ll create in a minute and sets the DATABASE_URL environment variable to use it.
Pick any region close to you. Just make sure to remember your choice, because you want the volume to be in the same region.
Answer no to setting up a Postgres database (haha), and also no to deploying. We need the volume first, so set it up with fly vol create:
$ fly vol create data -s 1
? Select region: Frankfurt, Germany (fra)
ID: vol_gez1nvxypen4mxl7
Name: data
App: my-sqlite-app
Region: fra
Zone: d7f9
Size GB: 1
Encrypted: true
Created at: 04 Nov 22 10:09 UTCNow, run fly deploy, and the Fly builder will build your Docker image, deploy it to your selected region, and start it up!
There’s only one more thing to do: run the migrations. Do that with a POST request to the /migrate/up path using your favourite tool. Mine’s HTTPie:
$ http post https://my-sqlite-app.fly.dev/migrate/up
HTTP/1.1 200 OK
content-length: 0
date: Fri, 04 Nov 2022 10:18:37 GMT
fly-request-id: 01GH12CM0MR0Z50E8GDNY916Y7-fra
server: Fly/c86be2f07 (2022-11-03)
via: 1.1 fly.ioAnd voila, your web app powered by SQLite is now in the cloud! Congratulations. Have a celebratory coffee and cookie. You deserve it. 😄
Are there any downsides to this approach? Yes. Every time you deploy, fly.io has to take your app offline for a few seconds, because two containers can’t have the same persistent volume attached at once. For many web apps, it’s perfectly fine to be offline for a few seconds once in a while. But if not, look out for the distributed SQLite things happening in the space. 😎
Resources
This article wouldn’t have been possible without these excellent resources (in no particular order):
- "I’m All-In on Server-Side SQLite" by Ben Johnson
- "Building Production Applications Using Go & SQLite" from GopherCon 2021, also by Ben Johnson
- "Consider SQLite" by Wesley Aptekar-Cassels
- The official SQLite documentation
- "One process programming notes (with Go and SQLite)" by David Crawshaw
- "The Untold Story of SQLite With Richard Hipp" on the CoRecursive podcast
About
I’m Markus 🤓✨. I’m passionate about simple & boring but useful software. So we can build the things that actually matter.
Want to learn Go web and cloud development? I’ve got online Go courses! 😎
Need someone to do it for you? I do software consulting.
Enjoyed this? Want my newsletter? No spam. Instant unsubscribe any time.
